HashML
简介
HashML 是酷克数据基于业界领先的云数仓产品HashData自主研发的一款AI开发工具,能够为开发者提供简单易用、算法先进、性能卓越、效果优异的AI开发体验。HashML为开发者提供了丰富的AI算法和模型能力,当前提供Python和SQL两种编程语言接口,仅需几行代码就能开启模型训练、推理预测,在统一的框架下支持各种经典的机器学习、深度学习算法以及预训练大模型。HashML作为HashData的一个扩展实现,与数仓共享统一的存储和计算资源,随数仓的部署提供开箱即用的AI能力,大幅降低了系统部署的成本和复杂度,为开发者提供了统一的数据查询、分析、建模环境。
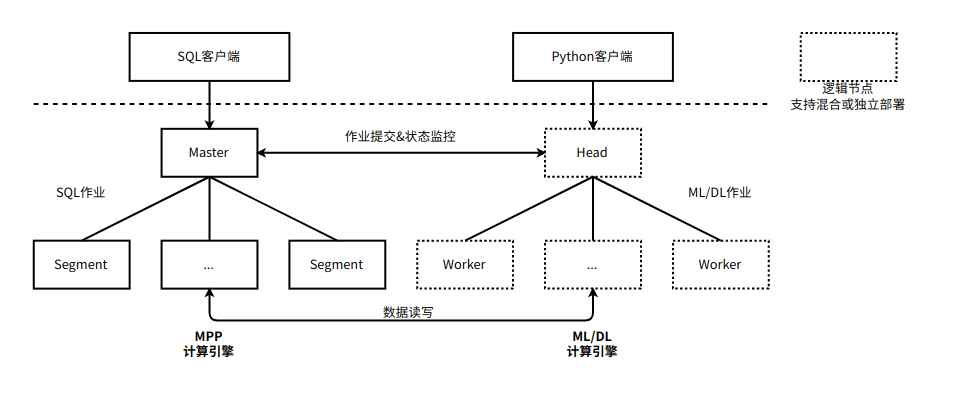
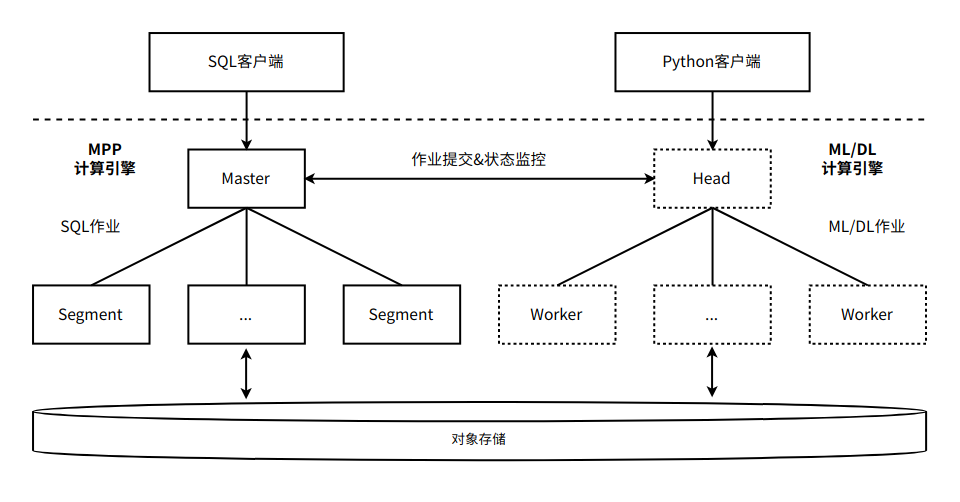
现有数据库内ML解决方案的局限性
传统的数据库内机器学习解决方案在应用过程中存在一些不足,包括:
- 支持的算法种类有限,且偏传统算法居多,如支持向量机、线性回归、决策树等;
- 对深度学习的支持比较有限,且受限于实现方式的约束,运行效率往往较低,影响模型的训练速度和训练精度;
- 数据并行训练缺乏灵活性,难以根据数据规模和模型复杂度进行调整,导致训练效率不能达到最优;
- 新算法开发难度较大,开发人员学习成本高;
- 与第三方数据科学工具互操作性较差。
这些局限性意味着,当数据科学家需要使用自定义算法、主流的深度学习算法、或流行的第三方数据科学工具时,需要考虑使用多种孤立的系统,这将增加数据管理和模型开发的复杂度。
HashML为数据库内ML提供了一种新方案
为了克服上述限制,HashML基于HashData领先的数据处理架构,利用先进的分布式计算、GPU加速、自适应算法等技术,并采用更加灵活的软件架构设计,可以更好地满足数据科学家的需求。
-
HashML提供了广泛的算法支持,特别是通过对深度学习框架的支持,能够支持各种深度神经网络算法;
-
新算法的开发和引入变得非常容易,客户仅需关注神经网络结构的定义和实现,就能开发一种全新的深度神经网络算法;
-
HashML支持分布式并行训练和推理预测,能够根据数据规模和模型复杂度灵活的调整并行度,大幅提高了模型训练和推理预测的效率;
-
HashML支持GPU加速,通过多机多卡分布式计算能够进一步提升运算效率;
-
HashML提供标准、统一、简洁的API接口,大幅降低了应用门槛;
-
HashML支持Python和SQL两种编程语言接口,客户可以根据个人偏好自主选择;
-
HashML通过Python接口能够与繁荣的数据科学生态相融合,为数据科学家和机器学习工程师提供丰富的开发工具。
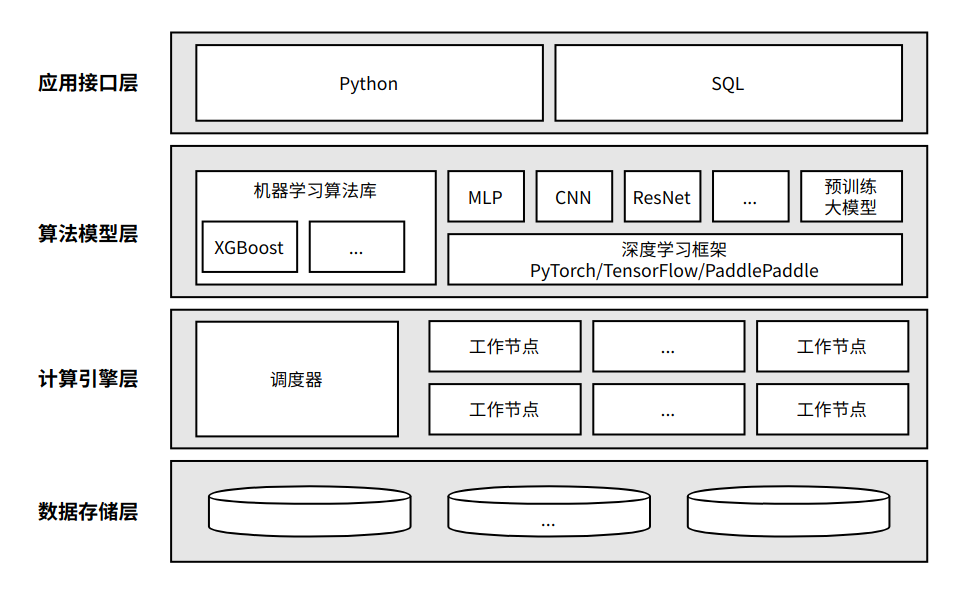
产品特色
简单易用
HashML首要设计目标就是简单易用,希望客户能够无门槛使用各种经典和最前沿的AI算法和模型能力来解决实际业务问题。为了实现这个目标,HashML对编程接口做了高度抽象和标准化,允许客户只编写少量代码就可以完成从数据加载到数据处理,再到模型训练、模型部署和推理预测到全流程建模。另外,HashML还提供了自动机器学习(AutoML)高级建模能力,通过自动对模型超参数进行搜索,在平衡计算资源开销的前提下自动帮客户实现更好的建模效果。HashML提供了SQL和Python两种编程语言接口。对于习惯使用SQL的客户,可以通过熟悉的SQL语言先完成数据的预处理,然后调用HashML提供的UDF进行模型训练和推理预测。对于习惯使用Python的客户,可以用纯Python的方式实现全流程建模,在使用HashML提供的功能的同时,灵活、按需使用任何第三方Python库。
算法先进
HashML的另一特色就是算法先进。HashML不仅提供了各种经典的机器学习算法(如XGBoost、LightGBM、GLM等效果好、可解释性强的梯度提升决策树算法),还通过支持主流的深度学习框架(如PyTorch、TensorFlow、PaddlePaddle等),能够支持各种深度学习算法(如MLP、CNN、ResNet等)。此外,HashML还支持最新的预训练语言大模型技术(如BERT、GPT等),能够对百亿到千亿级参数LLM进行微调(Fine Tuning)。微调是指在一个预训练模型的基础上,基于客户业务数据对模型进行二次训练以适应新的任务。HashML提供了方便的API来执行微调,使得开发人员可以快速高效地构建面向业务垂直场景的大模型,大幅降低了大模型技术的应用门槛,同时通过低成本私有化部署保证了客户数据安全。
上述算法是基于不同的数学原理和方法构建的,旨在解决不同类型的问题,从文本分类、图像识别到自然语言处理,以及推荐系统、异常检测、金融风控等各种领域。这些算法的支持使得这个工具箱可以应用于各种不同的数据科学和机器学习任务,用户可以更轻松地构建和训练自己的模型,并在实际应用中取得更好的结果。在实践中,数据科学家和机器学习工程师可以根据具体任务和数据集的性质选择合适的算法。
性能卓越
通过将HashData数据分析处理能力和HashML分布式机器学习能力相结合,可以提供性能卓越的据科学计算环境。通常情况下,客户可以根据业务规则,对数据库中存放的多个关系表利用SQL进行分析处理,通过SQL引擎实现大规模数据的高效预处理,为后续的机器学习任务做好准备。接下来,通过调用HashML提供的API,实现多机多卡分布式训练和推理预测。无论使用SQL还是Python,都可以方便快捷地使用统一的HashData平台来处理大规模数据,并利用分布式训练和批量推理功能进行高效的模型训练和推理。
开发者友好
HashML不仅内置了丰富的机器学习算法和深度学习算法,也允许客户根据需要定制开发新对算法。通过对算法开发框架精心封装,使得开发者在充分理解算法原理的基础上,只须关注网络结构的定义和实现,用少量代码就能完成新算法的开发和引入。新算法开发完成后,就可以自动具备框架所提供的分布式并行训练和推理能力。