常见问题
Sql中slices数超出gp_max_slices设置
一个query中如果slices太多,会占用更多集群资源影响集群性能,在生产环境一般会设置gp_max_slices为50,超过设置query不会执行,这个问题一般是query中关联的表很多导致,可以将query中一些操作落地成临时表,减少sql中关联的表.
锁等待问题
一个query执行非常慢,很长时间没有返回结果,很有可能是等待锁造成的
SELECT database,pid,mode,granted,mppsessionid FROM pg_locks where relation=xxxxx;
如果granted是f,那query处于锁等状态
SELECT lorpid,lormode,lorgranted,lorcurrentquery FROM gp_toolkit.gp_locks_on_relation where lorrelname=xxxxx;
通过上面查询找到lorgranted=t的lorpid,用select pg_cancel_backend(lorpid);解锁.
视图权限问题
如果报查询视图没有权限,然后赋予select权限后还是没有权限,那是因为视图的owner必须有访问源表的权限,如果视图的owner没有查询源表的权限,那么所有用户,即使超级用户也无法通过这个视图查询数据.
连接数过多问题
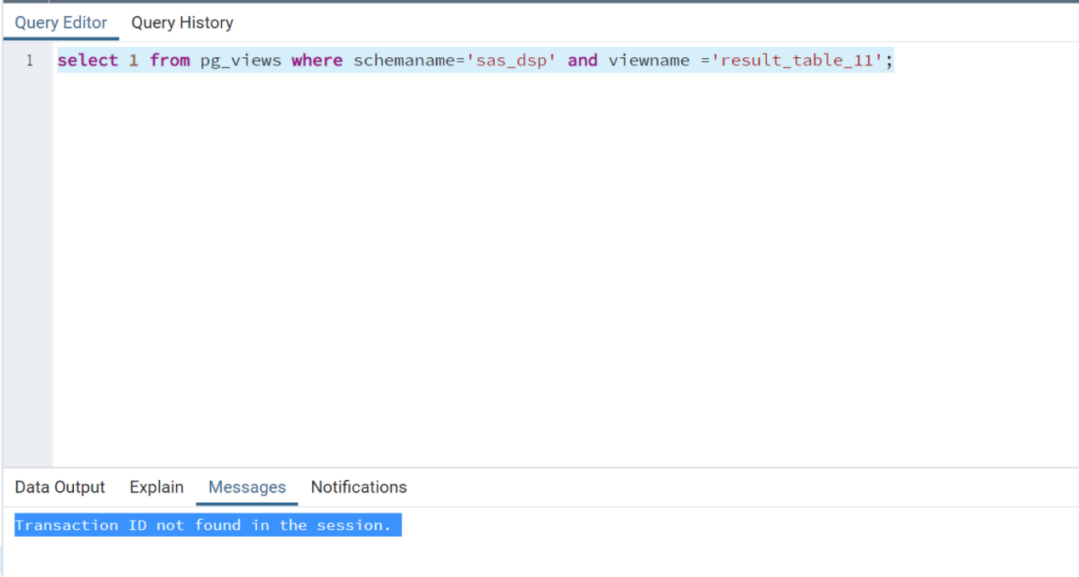
这个问题是超出里集群的连接数pgadmin4有可能产生这个报错,可以杀掉集群的idle连接来释放.
垃圾回收问题
在 HashData 中删除、更新数据记录时,会产⽣新的 tuple 版本,旧版本通过行头部标记为已删除以及 被哪个事务删除的。因此频繁的更新后,或者批量量的删除数据后,需要通过 vacuum、 vacuum full、 alter table redistribute 命令,回收那些旧的版本。
- AO 表使⽤ vacuum 可以回收部分垃圾((当某些数据⽂件垃圾记录超过设定⽐例时,可收缩文件大小), vacuum 时堵塞 UPDATE 和 DELETE,但是不不堵塞 INSERT。收缩⽂件大小,可能导致索引膨胀。
- HEAP 表 vacuum 可以回收垃圾,但是不收缩⽂件。
分析查询效率降低问题
SQL运行慢,性能低,有时长时间运行未结束,主要可以从以下几方面进行分析:
- 使用EXPLAIN命令查看SQL执行计划,根据执行计划判断是否需要进行SQL调优。
- 分析查询是否被阻塞,导致语句运行时间过长,可以强制结束有问题的会话。
- 审视和修改表定义。选择合适的分布列,避免数据倾斜。
- 分析SQL语句是否使用了不下推的函数,建议更换为支持下推的语法或函数。
- 对表定期做vacuum full和analyze,可回收已更新或已删除的数据所占据的磁盘空间。
- 检查表有无索引支撑,建议例行重建索引。
- 对业务进行优化,分析能否将大表进行分表设计。
资源隔离的问题
采用资源队列管理内存和资源,数据库的资源队列为管理集群负载提供了一种强有力的机制,队列可以被用来限制活动查询的数量以及队列中查询可使用的资源量。当查询被提交给数据库时,它会被加入一个资源队列,资源队列会决定该查询是否应该被接受并且何时有资源可用来执行它。集群为所有租户分配预定义好的资源队列,租户间计算资源物理上完全隔离。每个登录用户(角色)都被关联到单个资源队列,任何该用户提交的查询都由关联的资源队列处理,如果没有为用户的查询明确地分派一个队列,则会由默认队列pg_default处理。
超大规模部署的问题
HashData采用计算存储分离的架构,单集群提供超大规模部署能力。单集群的物理服务器规模可以到数千台。单个集群内的计算节点(实例)可以达到数万个。提供海量数据的存储能力,单数据库可以支持创建10000张以上的数据表,存储数据可以达到PB级。目前在金融行业的落地案例已达到近20000计算节点规模。
软硬件平台兼容性问题
兼容国内外ARM架构服务器和X86架构服务器,软件平台与硬件无强绑定关联性,支持各类主流芯片,已完成与飞腾、鲲鹏、海光等芯片的适配认证。兼容支持各类主流芯片路线服务器,已完成与浪潮、华为等服务器产品的适配认证。兼容主流服务器操作系统,包括但不限于Redhat、CentOS、麒麟、统信等。